
Le numim conexiuni asimetrice pentru ca banda disponibila pentru download este (mult) mai mare decat banda disponibila pentru upload.
Conexiunile internet terestre asimetrice, fie ca sunt DSL sau DOCSIS, au fost candva foarte populare in principal pentru ca:
– dezvoltarea lor a beneficiat de o retea fizica deja existenta, vezi tehnologia DSL;
– operatorii au putut impusca doi iepuri dintr-o data, oferind atat abonamente TV, cat si abonamente internet, vezi tehnologia DOCSIS.
Pierderea in popularitate are in principal doi vinovati:
– continutul consumat online, transferuri P2P, FTP, programe HD, cere o latime de banda din ce in ce mai mare;
– serviciile real-time, voce si video, impun valori stricte pentru delay si jitter.
Tocmai ati contractat o conexiune internet 6 Mbps download si 512 Kbps upload. Veti beneficia de cei 6 Mbps download? Raspunsul nu poate fi un DA convingator si asta nu din ratiuni comerciale, ci pur din ratiuni tehnice.
Desi banda disponibila pentru download poate parea suficienta, throughput-ul TCP este afectat de caracterul asimetric al conexiunii, astfel ca nu veti beneficia complet de cei 6Mbps.
Protocolul TCP se bazeaza foarte mult pe mesajele ACK pentru:
– stabilirea unei noi sesiuni TCP;
– garantarea receptionarii datelor (TCP flow-control);
– depistarea si prevenirea congestiei (ACK self-clocking [2]).
Teoretic, pentru transferurile unidirectionale, UNI-to-UNi sau mouth-to-ear, putem determina daca avem suficienta capacitate upstream pentru a folosi la maxim capacitatea downstream calculand urmatorul raport:
k = (downstream/upstream):(data_size/ack_size) < 1
Parametru k arata cate pachete TCP trebuie sa fie confirmate de catre un pachet ACK, astfel incat sa se evite saturarea canalului upstream cu pachete ACK. Pentru un transfer FTP am putea avea urmatoarele valori data_size = 1424B, ack_size = 56B, astfel incat pentru conexiunea 6Mbps/512Kbps obtinem k = 0,33 < 1, deci teoretic putem sa folosim la maxim capacitatea de 6Mbps.
Dar ce se intampla atunci cand folosim capacitatea de upstream concomitent cu capacitatea downstream? Este foarte usor sa “umplem” cei 512Kbps si odata cu asta pachetele ACK vor fi primite cu intarziere sau deloc, fiind inlaturate inainte de a ajunge la destinatie, sursa traficului TCP.
Intarzierea pachetelor ACK este numita “ACK Compression”[2], denumirea facand referire la faptul ca mesajele ACK vor fi primite cu o spatiere temporala mai mare fata de cea a mesajelor TCP reprezentand transferul util de date, insa comprimate in timp, un numar mai mare de mesaje ACK per interval de timp.
“ACK Compression” influenteaza in sens negativ throughput-ul TCP, natura traficului TCP si latenta conexiunii.
TCP foloseste mecanismul de “self-clocking” pentru a determina rata optima la care sa trasmita pachetele pentru a nu aparea congestii. Acest mecanism presupune adaptarea ratei de transfer in functie de rata de primire a mesajelor ACK. Daca mesajele ACK vor fi intarziate din cauza limitarii de banda pe upstream, atunci rata cu care vor fi trimite noile pachete TCP va scadea desi pe downstream exista suficienta capacitate libera.
Un numar mai mare de mesaje ACK primite pe o unitate de timp va determina traficul TCP sa capete un caracter “bursty”. TCP “Congestion Window” (cwnd) [3] este crescuta exponential de fiecare data cand este primit un mesaj ACK si atata timp cat nu avem pierderi de pachete, astfel mai multe date vor fi trimise intr-o unitate mai mica de timp urmand apoi o pauza cauzata de intarzierea primirii mesajelor ACK.
In momentul in care mesajele ACK sunt inlaturate inainte de a ajunge la destinatie (sursa traficului TCP) throughput-ul TCP va fi deasemenea afectat negativ deoarece un numar mai mic de mesaje ACK primite inseamna atat crestere lenta a “congestion window”, implicit subutilizarea capacitatii downstream, cat si retransmiterea frecventa a datelor. Deasemenea pierederea mesajelor ACK face aproape imposibila folosirea metodei “fast retransmit”[3]. TCP va trece astfel, de fiecare data cand un pachet este pierdut, prin “slow start” [3] ceea ce inseamna ca valoarea “congestion window” va fi resetata de fiecare data la 1, throughput-ul TCP fiind semnificativ redus.
Urmatoarele doua grafice ofera o imagine clara a ceea ce se intampla pe “linie” intr-o situatie practica [1]:
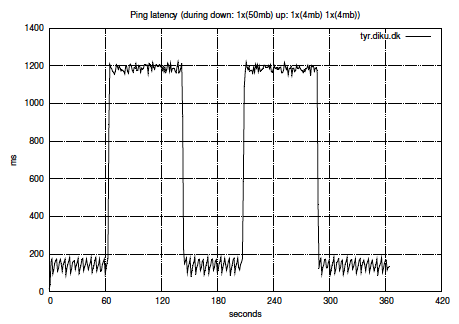 |
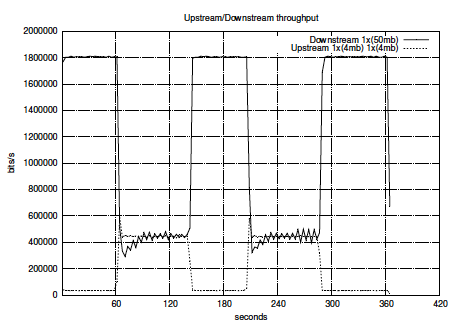 |
Atasat este un fisier .txt cu o captura de pachete din timpul unui transfer TCP/FTP, upload pe server-ul X. Se poate observa ca dupa fiecare doua pachete server-ul X trimite ACK. Stiam ca expeditorul anunta cantitatea de date pe care o poate trimite (cwnd), respectiv destinatarul anunta cantitatea de date pe care o poate primi (rwnd), iar minimul dintre cele doua este ales (window size) pentru a reprezenta cantitatea de date trimisa de expeditor dupa care acesta se asteapta la un ACK din parte destinatarului.
Ce se intampla in acest caz? De ce server-ul trimite ACK dupa fiecare doua pachete?
[1] optimization-of-tcpip-traffic-across-shared-adsl
[2] http://www.faqs.org/rfcs/rfc3449.html
[3] http://www.faqs.org/rfcs/rfc2581.txt
Frumos articol, putina lume intelege aceste mecanisme.
As adauga ca o aproximare grosiera este ca pentru un download la viteza X se consuma X/10 pe upload. Daca uploadul este aproape de aceasta valoare (X/10), atunci orice consum suplimentar Y pe upload scade banda disponibila pe download cu 10Y. In acest caz nu prea e convenabil sa faci share (upload) fara limitare de banda.
Despre problema propusa, daca imi amintesc bine ambele capete ale conexiunii anunta cat pot sa primeasca, si fiecare calculeaza local (fara sa anunte) fereastra de congestie. Daca se pierd packete, emitatorul scade numarul de packete pe care le trimite fara a primi confirmarea. La limita nu trimite urmatorul packet pana nu primeste ack la packetul precedent. In functie de delay-ul (timpul de ping) intre capete, viteza este limitata la MTU/delay. Trimiterea de ack se poate face la fiecare packet, sau serverul poate trimite un singur ACK daca primeste mai multe packete contigue intr-un interval scurt de timp.
Ar mai fi interesant de discutat despre sincronizarea mai multor conexiuni TCP, cand toate vad ca exista banda libere, apoi toate detecteaza congestia si elibereaza prea multa banda. Apoi despre ACK-uri care vin prea tarziu, dupa ce serverul a re-transmis deja packetul din cauza faptului ca delay-ul a variat mai mult decat estimase trimitatorul.
Este o lume complexa, unele consecinte nu au fost prevazute nici de catre cei care au gandit TCP-ul. E bine ca exista pasionati care incearca sa ii descopere tainele.
O idee interesanta care iti vine in minte dupa ce citesti acest articol este sa incerci sa aproximezi viteza de transfer (per TCP flow) in functie de RTT (delay). As vrea sa dezvolt un pic ceea ce a spus Mihai in observatia lui legat de limitarea vitezei la MTU/delay. Din cate cunosc eu, aceasta formula este valabila doar la inceput, cand “window size”(= IW sau initial window) se stabileste ca fiind:
– SMSS (sender’s maximum segment size) calculat in functie de RMSS (receiver’s MSS) obtinut in faza de “SYN handshake”
– MTU-ul descoperit intre sender si receiver in caz ca exista “Path MTU Discovery”
– MTU de pe interfata pe care se trimite pachetul
– 536 bytes in absenta altei informatii.
TCP-ul se fereste de congestie si de aceea seteaza o valoare mica pentru window size la inceput. Ulterior aceasta valoare incepe sa creasca insa fiind un camp de 16 biti din header-ul TCP nu poate depasi 65,535 bytes.
Fac o paranteza ca sa adaug ca se poate folosi “window scale option” pentru a obtine “window size” pe 30 de biti (cum apare si in captura atasata de tine Ionut) dar eu voi lua ca referinta cei 16 biti. Conexiunile de mare viteza folosesc toate “scale option” deci un “window size” mai mare de 65,535 este frecvent in zilele noastre.
Asadar window size incepe sa creasca incepand cu MSS/MTU sau 536 bytes dar nu poate depasi 65,535 de bytes. Viteza calculata ca fiind window size/RTT creste si ea de la MTU(bytes)/RTT cum a specificat Mihai pana la 65,535(bytes)/RTT. Notiunea de echilibru in TCP este des intalnita pentru ca tot timpul se coordoneaza sender-ul, receiver-ul si reteaua asa cum ai descris si tu Ionut.
Haideti sa luam un exemplu concret: Avem o conexiune de 100 Mbps de la un provider si vrem sa tragem ceva din reteaua lui(un singur flow TCP). RTT este de 2 ms iar TCP-ul negociaza window size la 6000 bytes. In acest caz putem afirma ca nu vom depasi o viteza mai mare de 48 Kbiti / 0.002 sec ~ 24 Mbiti pe un singur flow TCP.
Interesanta ideea de a posta acest articol despre TCP; ma astept la zeci de comentarii si pareri pentru ca intr-adevar se pot spune foarte multe.
TCP Window Scale nu este un camp separat in header-ul tcp, campul Options este folosit ca si pentru comunicarea MSS. Initial cand a fost gandita expansiunea pentru Window Size, s-a spus ca noul mecanism de scaling va fi folosit pentru”fat-pipes” sau pentru “Long Fat Networks” 😀
Doar mesajele SYN/[SYN ACK] contin valoarea Window Scale. Window Scale nu specifica intrinsec o noua valoare a ferestrei de transmisie, ci specifica un factor (de exemplu 3) care ne da puterea lui 2 (acest numar este numit “shift count”) cu care trebuie inmultita valoarea curenta a ferestrei pentru a obtine valoarea noua a fereastrei sau “maximum receive buffer space” (2^3*WindowSize).
“Maximum receive buffer space” este astfel comunicata catre celalalt capat al unei conexiuni TCP (valoare este folosita pentru “flow control”, pentru incercarea de a folosi la maxim atat “teava”, cat si buffer-ele de receptie a fiecarui capat al conexiunii TCP), insa valoare congestion window (valoare folosita pentru “congestion control”, pentru a nu supra-incarca “teava”) nu este comunicata. Totusi ambele capetele ale conexiunii TCP vor folosi minimul dintre congestion window si window size pentru a determina valoarea maxima de date pe care o vor pune pe teava pana asteapta confirmarea primirii lor.
Optiunea Window Scaling trebuie suportata de ambele capete ale conexiunii TCP. Initiatorul conexiunii TCP trimite optiunea in mesajul SYN initial si numai in cazul asta primeste ca raspuns, in mesajul [SYN,ACK], optiunea Window Scaling a celuilalt capat.
Dar ce se inampla apoi? Sesiunea TCP a fost stabilita, Window Size-ul a fost negociat, insa caracteristicile conexiunii se schimba: RTT creste sau conexiunea HSDPA devine GPRS …
Stiu doua lucruri care se pot intampla:
– RTT canal upstream creste => “self clocking” va scadea rata de transfer pe canalul downstream;
– conexiunea incepe sa piarda pachete => sesiunea TCP va trece prin “slow start” sau “fast retransmit”, valoarea congestion window fiind acum luata in calcul si nu valoarea window size.
De acord ca “Window Scale Option” nu e camp separat in headerul TCP, nici nu am spus asta; e doar un shift de biti care permite “window size” sa ajunga de la 16 la 30 de biti (deci “shift count” poate fi maxim 14). Fiind doar o paranteza nu am vrut sa intru in detalii.
Vreau sa va provoc cu doua noi intrebari:
1. De ce wireshark spune ca pachetul 3534 este ACK pentru 3533 “This is an ACK to the segment in frame: 3533″ desi este un pachet FTP-DATA?
2. Ce se intampla cu pachetele ACK din aceasta captura?
Daca luam exemplul pachetului 3535, “Acknowledgement number” este 2518489, valoare pe care o gasim ca si “Sequence number” pentru pachetul 3523.
Nu ar fi trebuit ca pachetul ACK sa ceara prin “Acknowledgement number” urmatorul pachet (“Acknowledgement number” = urmatorul “Sequence number”)?
Poate ca tie ti se pare familiar outputul de Wireshark pe care l-ai atasat insa pe mine m-a apucat durerea de cap cand am inceput sa ma uit prin el. E complicat sa analizezi fisiere .txt de mii de linii … o idee ar fi fost sa atasezi un .dump pe care sa-l deschidem si noi cu Wireshark. Cand spui serverul X te referi la ip-ul x.x.x.x din captura ?
Cred ca raspunsul la intrebarea din post-ul initial se refera la delayed ACK. Dupa cum se mentioneaza in RFC1122, atat timp cat RTT dintre doua segmente nu e mai mare de 200ms se va trimite ACK la al doilea segment. Microsoft tine cont de acest RFC insa acest comportament se poate modifica chiar si pe Windows daca adaugi in registri o intrare de tip TcpAckFrequency mai mare decat 2.
Da, corect, este vorba despre “Delayed ACK”, uneori atat de util, alteori atat de daunator (a se vedea interactiunea dintre algoritmul Nagle si Delayed ACK). Multumesc pentru raspuns!
Ai dreptate, este mult mai usor de parcurs un output libpcap, se pate descarca de aici
Nice dispatch and this mail helped me alot in my college assignement. Gratefulness you on your information.
Hello,
foarte tare aceasta discutia,dar daca se poate sa pasam discutia si catre conexiuni cu banda garantata..ce se intampla in acest caz?
@kalvin daca garantarea upload/download este bine proportionata, nu poate decat sa te ajute.